
Coding agents work, State of AI report, inference request, GitHub Copilot and Cursor updates
EPAM AI SDLC experts dive into the evolution of autonomous coding agents and their role in transforming enterprise workflows.
This digest was prepared by:
- Alex Zalesov, Systems Architect
- Aliaksandr Paklonski, Director of Technology Solutions
- Tatsiana Hmyrak, Director of Technology Solutions
.webp)
This issue explores the normalization of autonomous coding agents and the infrastructure surrounding them.
- A hands-on tutorial demystifies how a coding agent writes code in just a few hundred lines of Go, while a deep dive into vLLM traces every stage of a high-throughput inference request.
- ICONIQ’s State of AI 2025 report grounds these technical pieces in market reality, showing where enterprises are deploying agentic workflows and how they choose models.
- On the tooling front, GitHub Copilot debuts a dedicated Agents page and expands Anthropic model access, giving teams finer control and stronger reasoning options.
- Cursor counters with structured task management, repository-wide PR search, and latency improvements that cut time-to-token by 30%.
Together these updates move agentic development from promising prototype to everyday practice, with clearer workflows, faster feedback loops, and enterprise-grade transparency.

Coding agent under the hood
This article is for readers who want to understand how coding agents actually work under the hood, beyond surface-level demos or marketing claims. Thorsten Ball’s tutorial provides a hands-on, step-by-step introduction that breaks down each component of a code-editing agent, from conversational context management to tool invocation and file operations. The guide is pragmatic and approachable, showing how to assemble a fully functional agent in just a few hundred lines of Go code using the Anthropic API.
By following the tutorial, practitioners can demystify the inner workings of modern coding agents and gain direct experience building one themselves. The result is a working agent capable of editing and creating code — demonstrating capabilities similar to commercial tools like Cloud Code or Gemini CLI.
State of AI 2025 report
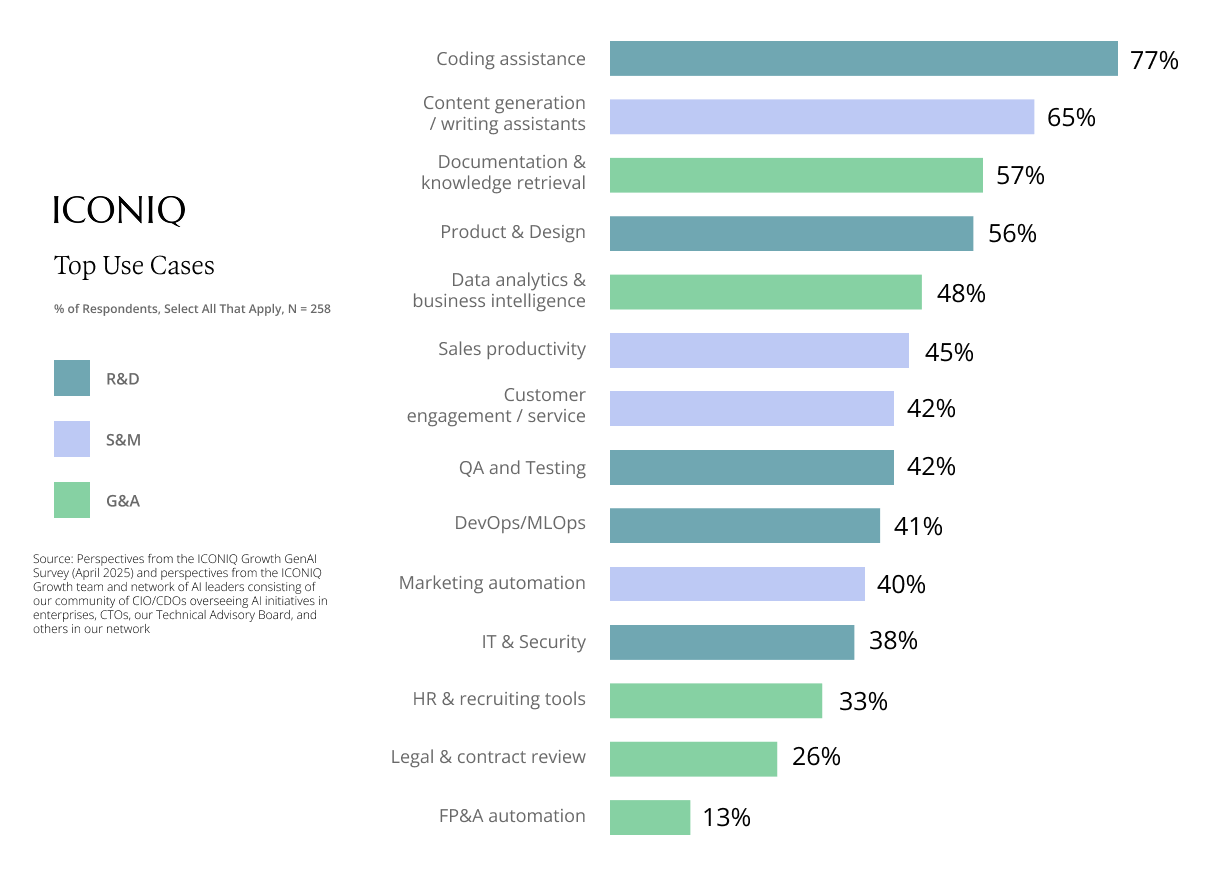
The 2025 State of AI report, based on a survey of 300 executives building AI products, offers a practical look at how companies are adopting AI.
Key questions addressed in the report include:
- What types of projects are companies building (agentic workflows, vertical/horizontal apps, platforms)?
- Are teams using third-party APIs, fine-tuning existing foundational models, or developing models from scratch?
- What are the top considerations when choosing a foundational model for customer-facing use cases, and how do these differ from internal use cases?
- How do companies price their models — by seat, usage, or outcome?
Most companies use OpenAI as their primary model provider, often supplementing with one or two secondary models from Anthropic, Google, or Meta. Coding assistants, writing assistants, and documentation retrieval are the top productivity use cases. The report also details the tech stack for model hosting, evaluation, and coding assistance, providing a reference point for teams planning their own AI adoption.
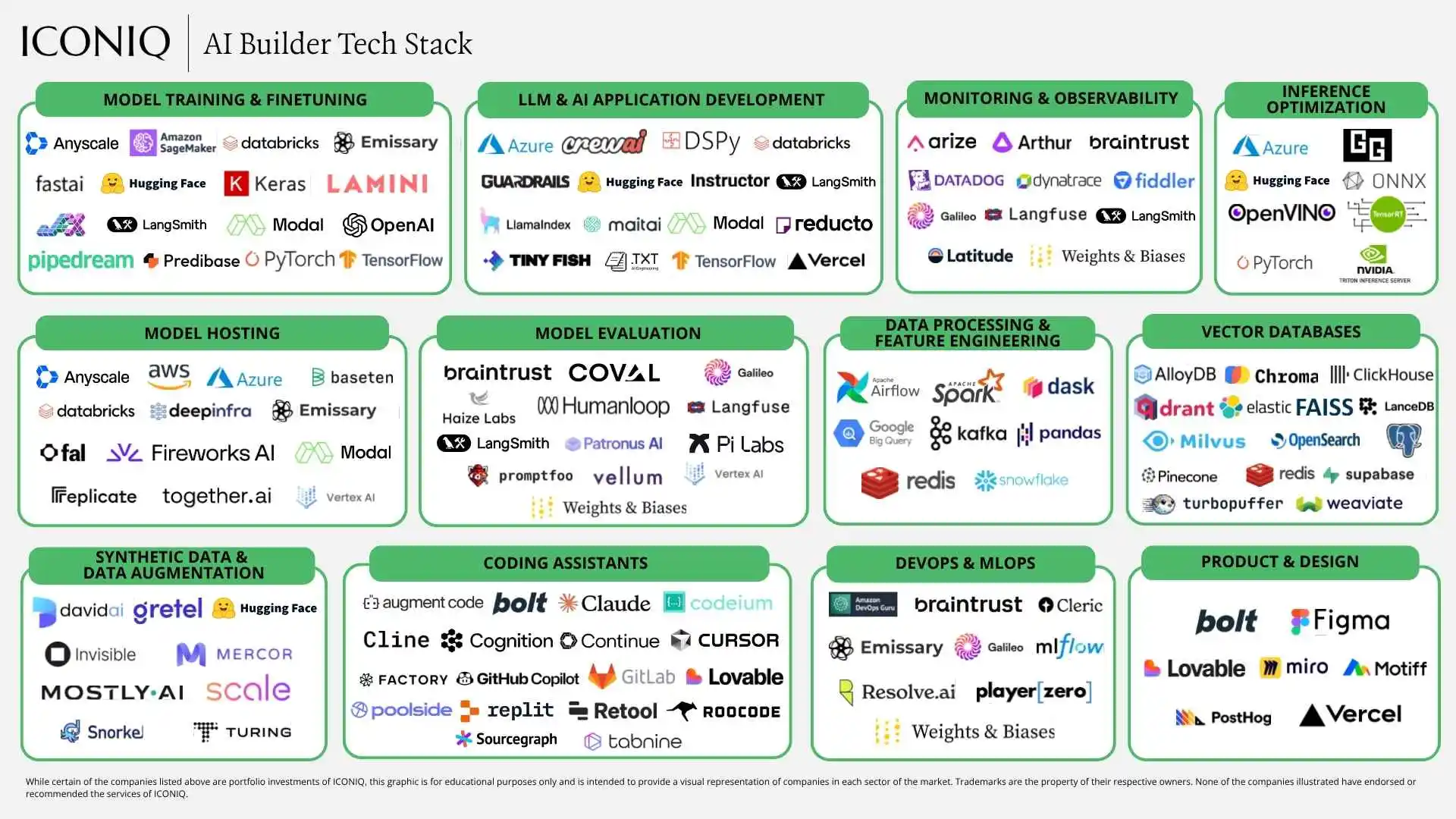
Source: https://www.iconiqcapital.com/growth/reports/2025-state-of-ai
Life of an inference request
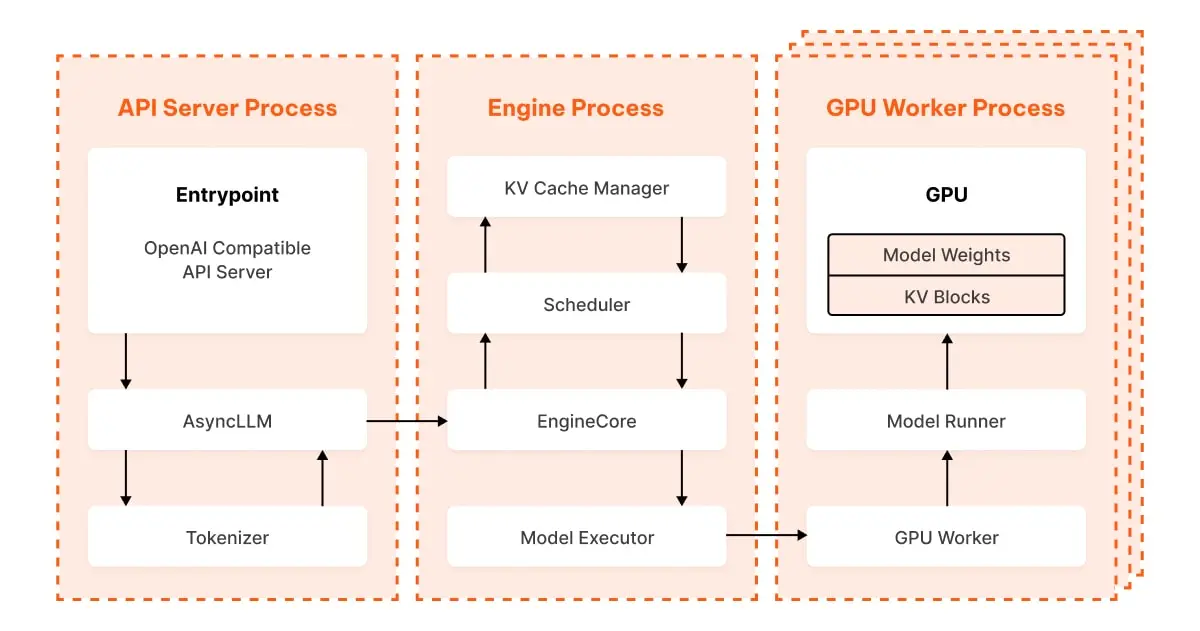
The article “Life of an Inference Request (vLLM V1)” offers a deep dive into the architecture and request lifecycle of vLLM, an open-source inference engine designed for efficient large language model (LLM) serving. Readers interested in the practical realities of deploying and scaling LLMs in production will find this post especially valuable, as it goes beyond surface-level descriptions to detail how vLLM orchestrates high-throughput, low-latency inference across multiple GPUs.
The post walks through each stage of an inference request, from the moment a prompt arrives at the OpenAI-compatible API server, through asynchronous tokenization and inter-process communication, to the heart of the system: the EngineCore. Here, requests are continuously batched and scheduled for maximum GPU utilization, leveraging a paged KV cache system for efficient memory management. The article explains how vLLM’s scheduler and ModelExecutor coordinate to process requests in parallel, and how the system streams generated tokens back to clients in real time.
This technical breakdown is essential reading for AI engineers and platform teams evaluating or operating LLM inference infrastructure. It demystifies the inner workings of vLLM, highlights the architectural choices that enable its performance, and provides context for tuning or extending the system. By understanding the full journey of an inference request, readers can make more informed decisions about model deployment, scaling strategies, and system optimization.
Source: https://www.ubicloud.com/blog/life-of-an-inference-request-vllm-v1
GitHub Copilot
1. GitHub Copilot agents page
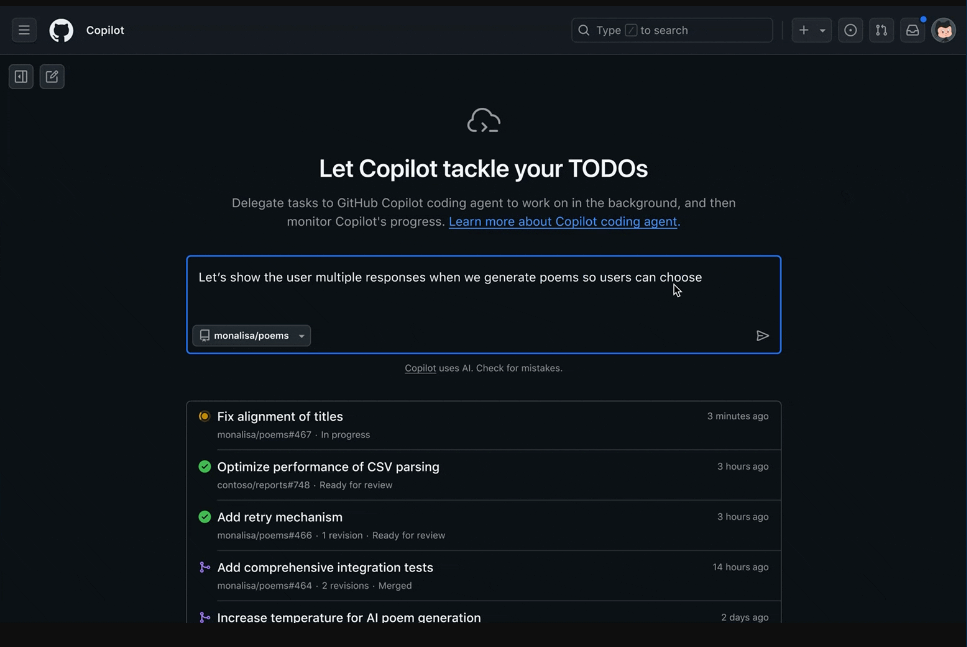
GitHub now provides a dedicated page to manage Copilot coding agents. From this page, you can type a task, pick a repository, and launch an autonomous agent to work on code. You also can assign issues to agents or start an agent from a Copilot chat in your IDE. The page shows active agent runs, finished tasks, and merged pull requests, so teams can see what agents are doing and what has been delivered.
Using Playwright MCP server coding agent can validate its work in the browser and reproduce assigned bugs.
The coding agent, previously available in Copilot Business and Enterprise plans, is now also included in the Copilot Pro plan.
Sources:
- https://github.blog/changelog/2025-07-02-agents-page-for-copilot-coding-agent-in-public-preview/
- https://github.blog/changelog/2025-07-02-copilot-coding-agent-now-has-its-own-web-browser/
2. Anthropic Claude Sonnet 4 and Opus 4 are available
Anthropic Claude Sonnet 4 model is now available to all paid GitHub Copilot plans. Claude Opus 4 is available for Copilot Enterprise and Pro+ plans.
Cursor
1. Structured task management

Agents now automatically generate structured to-do lists for complex tasks, breaking down long-horizon work into actionable steps with clear dependencies. Each to-do item can specify prerequisites, clarifying workflow order and making it easier to track progress across multi-step or dependent workflows.
To-do lists update in real-time as the agent works, with completed tasks marked off automatically. This provides users with transparent, up-to-date insight into what the agent is doing and what remains. The to-do list is visible directly in the chat interface, and — if Slack integration is enabled — also streamed into Slack channels for broader team awareness.
This structured approach improves predictability, context retention, and collaboration, helping users understand, monitor, and manage complex agent-driven workflows as they evolve.
Windsurf recently released a similar feature called planning mode. The key difference is that Windsurf creates and updates a file as the agent progresses, while Cursor keeps the to-do list in the chat window.
Source: https://cursor.com/changelog
2. PR indexing and search
Cursor now indexes all merged pull requests from your repository history, making summaries available in semantic search results.
The feature works with GitHub, GitHub Enterprise, and Bitbucket repositories. GitLab is not supported. Agents can fetch PRs, commits, issues, or branches into context using simple references like @[PR number], @[commit hash], or @[branch name].
PR search is part of codebase indexing and requires configured GitHub integration.
Source: https://cursor.com/changelog
3. Faster tab completions and reduced latency
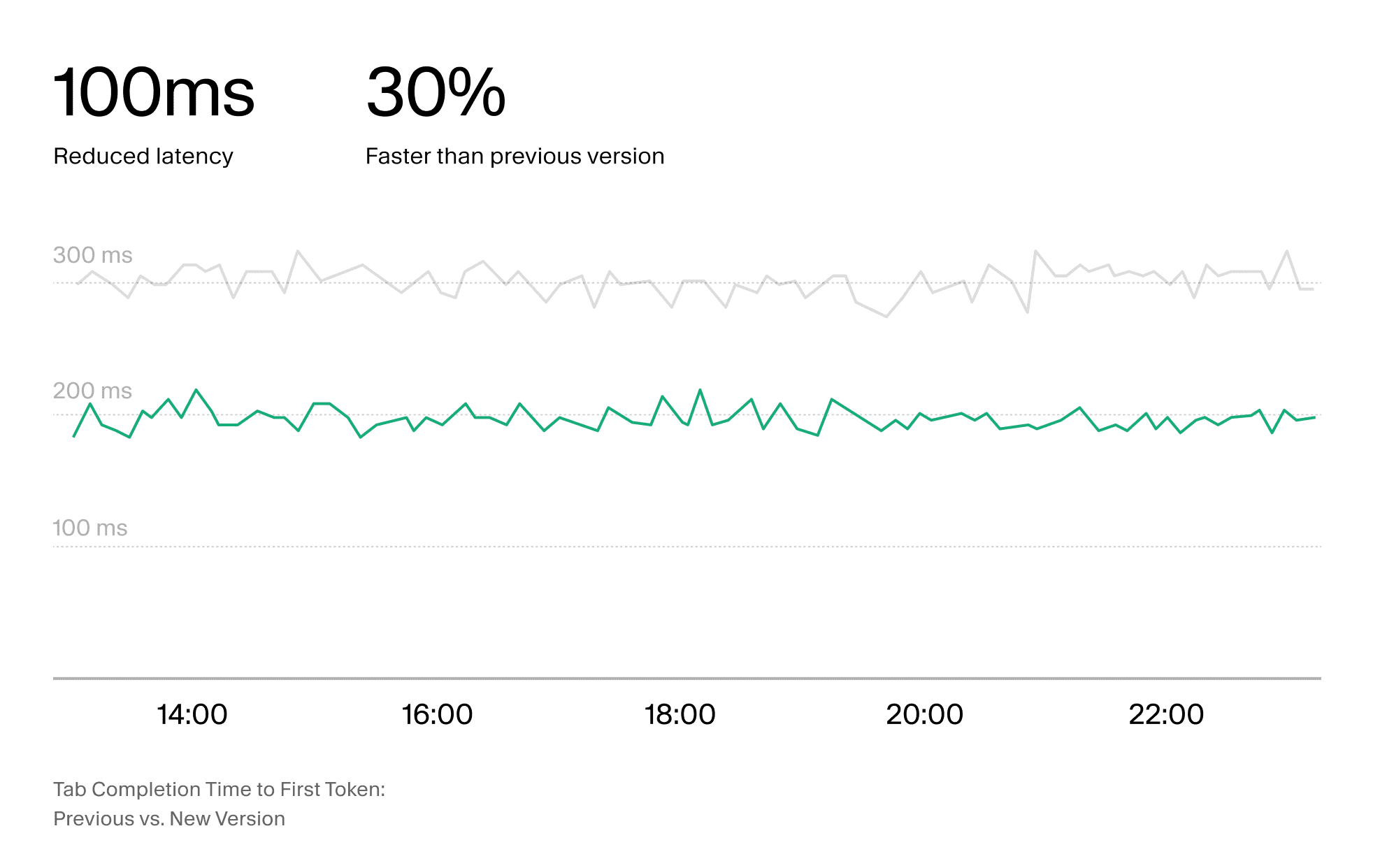
Cursor has improved the speed of its tab completions, reducing the time to first token (TTFT) by 30% and making completions approximately 100ms faster. These gains were achieved by restructuring the system’s memory management and optimizing data transfer pathways.
Lower latency directly improves the user experience for AI coding assistants, making interactions feel more responsive and efficient. While often overlooked, latency is one of key quality factors for developer productivity.
Source: https://cursor.com/changelog

_(1).png?auto=webp)
.png?auto=webp)