
Bridging the AI divide: insights from DX, METR, and McKinsey
EPAM AI SDLC experts explore how DX's utilization framework, GitHub Copilot's new updates, and Cursor integrations are addressing the AI adoption gap and transforming enterprise workflows.
This digest was prepared by:
- Alex Zalesov, Systems Architect
- Aliaksandr Paklonski, Director of Technology Solutions
- Tasiana Hmyrak, Director of Technology Solutions

This issue explores the growing divide between AI hype and enterprise results, highlighting where AI is delivering value, where it’s falling short, and how emerging tools are reshaping workflows:
- DX proposes a pragmatic utilization–impact–cost framework and cautions that “percent of code written by AI” overstates real gains.
- McKinsey report that most AI pilots still fail to move P&L, with measurable ROI concentrated in back‑office automation; both point to workflow learning and a shift toward agentic systems as the way across the GenAI divide.
- METR’s follow‑up shows current coding agents often pass tests yet fail to ship mergeable PRs, reinforcing the need for small diffs, stronger tests, and holistic gates (docs, typing, lint) beyond unit correctness.
- GitHub expands Copilot with “tasks anywhere”, auto‑generated commit messages, new model options (Gemini 2.5 Pro; Grok Code Fast preview), and deprecates Knowledge Bases in favor of Spaces.
- Cursor tightens workflow integration with Linear launch‑from‑issue, system notifications, and MCP Elicitation for structured inputs, and adds Grok 4 Code.
- The emphasis is shifting from raw model capability to embedded workflows, observability, and governed autonomy.
General news
Measuring the impact of AI on software engineering
Laura Tacho, CTO of DX, a company specializing in developer productivity measurement, discussed the realities behind the current wave of AI adoption in software engineering. She noted that mainstream headlines often misrepresent the true impact of AI, with vendors and ad-driven media amplifying misleading metrics such as the percentage of code written by AI. According to Tacho, these figures rarely reflect the actual changes in developer workflows or productivity.
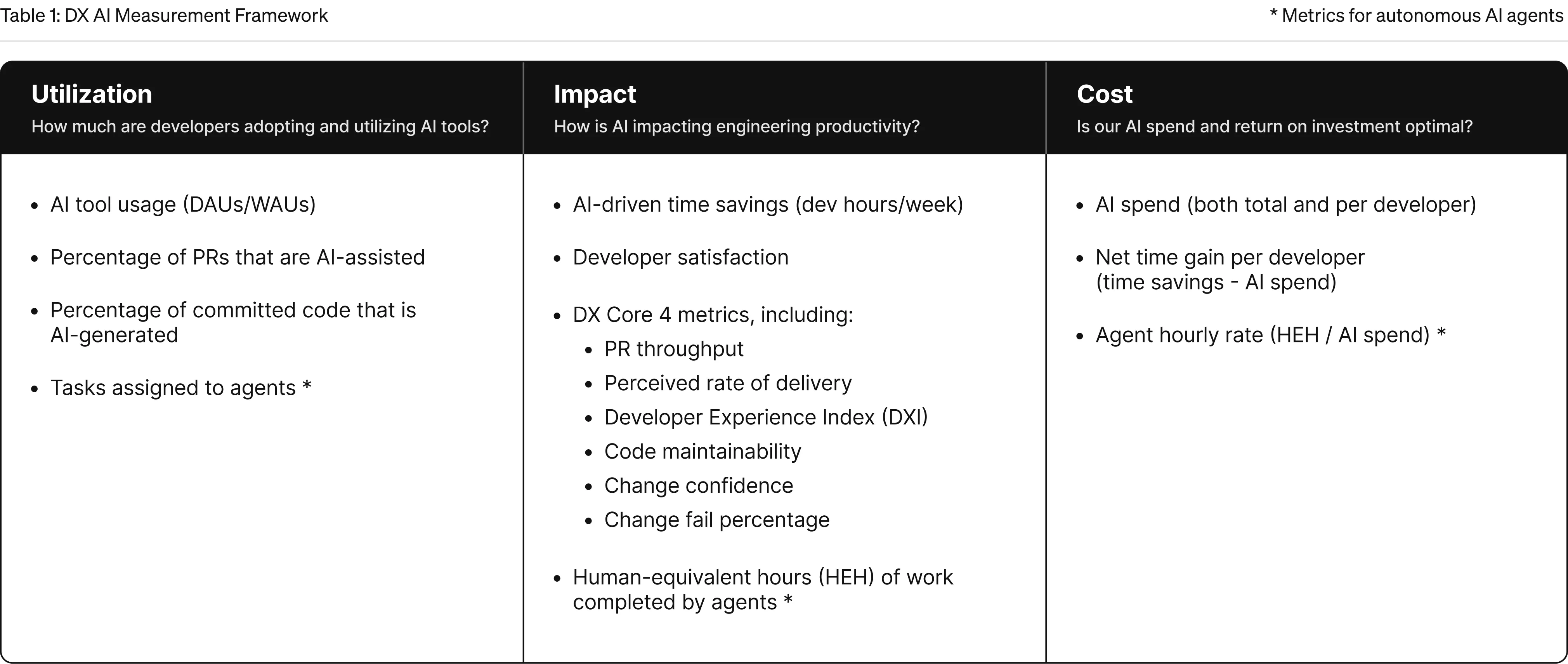
To address this, DX developed a framework that combines workflow and system data with self-reported measures, focusing on three main areas: utilization, impact, and cost. Utilization is tracked through metrics like daily and weekly active users and license coverage. Impact is measured by changes in velocity, a developer experience index, and factors such as cognitive load and flow. Cost is assessed by looking at license and consumption spend. Establishing baselines and running experiments are considered essential for attributing observed changes to AI adoption.
Booking.com raised weekly AI tool usage to about 65% by providing licenses and training to all employees. The adoption rate in this example is considered high across the industry. However, even with broad rollout, AI tools remain less effective for novel tasks or code with strict performance constraints.
Reported outcomes include measurable improvements in developer experience and velocity. WorkHuman, for instance, saw an 11% improvement in developer experience across the organization and a 15% increase in velocity among AI users. Among these users, throughput and task complexity also increased, which in turn required stronger quality controls.
.webp)
The most valuable use cases for AI tools today are not always code generation. Stack trace analysis and refactoring have been cited as areas where AI saves significant time. Unit test generation and well-structured tasks also perform well. Tacho pointed out that typing speed is not the main bottleneck in software development; rather, the overhead of code review often offsets the gains from code generation.
AI adoption is also prompting changes in software architecture and documentation. Clean service boundaries and explicit interfaces—always considered best practices—are now being more widely enforced, since codebases that follow these standards benefit more from AI-assisted tools. Documentation is moving toward an AI-first approach, with executable examples and minimal reliance on visual elements, to ensure that AI assistants can provide accurate, context-aware guidance. For AI assistants to be effective, codebases often need to be restructured with these needs in mind.
Quality and stability remain important concerns. AI tools make it easy to generate large PRs, but larger release size can risk stability and slow down throughput if not managed carefully. Organizations are responding by keeping changes small, strengthening tests and continuous integration, and monitoring reliability metrics such as error rates and mean time to recovery alongside speed.
Finally, the cost of developer tooling is increasing as generated tokens drive up per-developer expenses. Tacho compared this trend to the early 2000s, when Visual Studio licenses cost thousands of dollars per developer per year, suggesting that higher spend on developer tools is likely to become the norm.
Sources:
- https://www.youtube.com/watch?v=xHHlhoRC8W4
- https://getdx.com/research/measuring-ai-code-assistants-and-agents/
McKinsey Report
The McKinsey analysis begins by highlighting a persistent paradox in enterprise AI adoption: while approximately 78% of companies report using generative AI in at least one function, more than 80% see no material impact on earnings, and only about 1% consider their strategies mature. This disconnect frames what McKinsey calls the “gen AI paradox.” The report first examines the first generation of AI adoption, which was dominated by large language models (LLMs) and non-agentic systems.
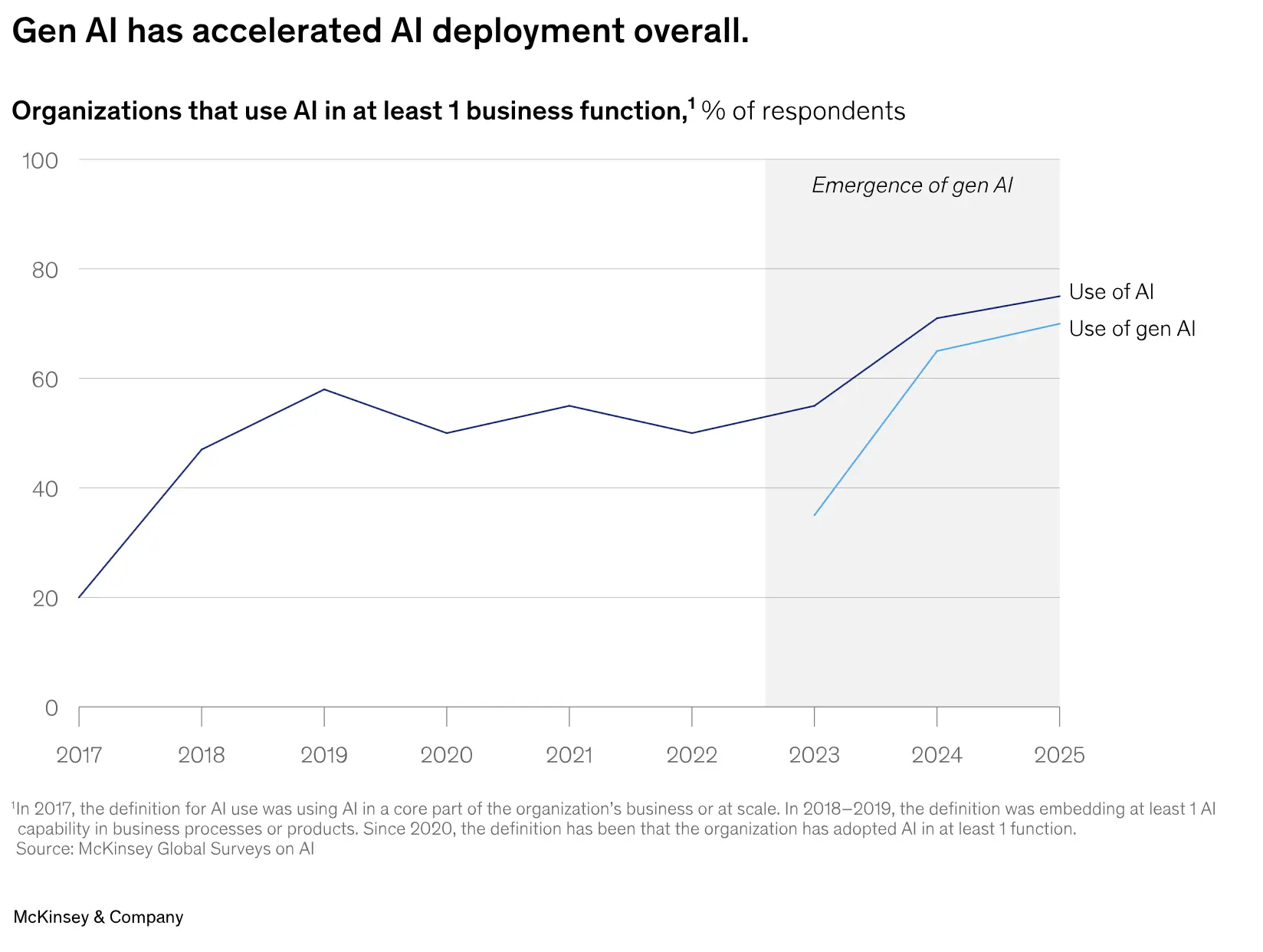
Early deployments focused on horizontal, off-the-shelf tools like copilots and chatbots. These scaled quickly and were widely adopted, but their benefits were often unclear and hard to measure. In contrast, high-impact vertical use cases—built for specific functions—rarely moved beyond pilot projects. They faced technical, organizational, data, and cultural barriers that limited adoption.
The narrative then shifts to the emergence of agentic systems as a potential turning point. Unlike earlier LLM-based tools, agents combine language models with memory, planning, orchestration, and integration capabilities. This enables them to act proactively toward goals, break down tasks, interact with both systems and people, execute actions, adapt based on feedback, and escalate when necessary. McKinsey introduces the concept of the “agentic AI mesh,” describing it as a new architectural paradigm for enterprise AI. This mesh is envisioned as a composable, distributed, and vendor-neutral layer that governs agent ecosystems. Its design principles include composability, distributed intelligence, layered decoupling of logic and memory, vendor neutrality through open protocols, and governed autonomy with clear policies and permissions.
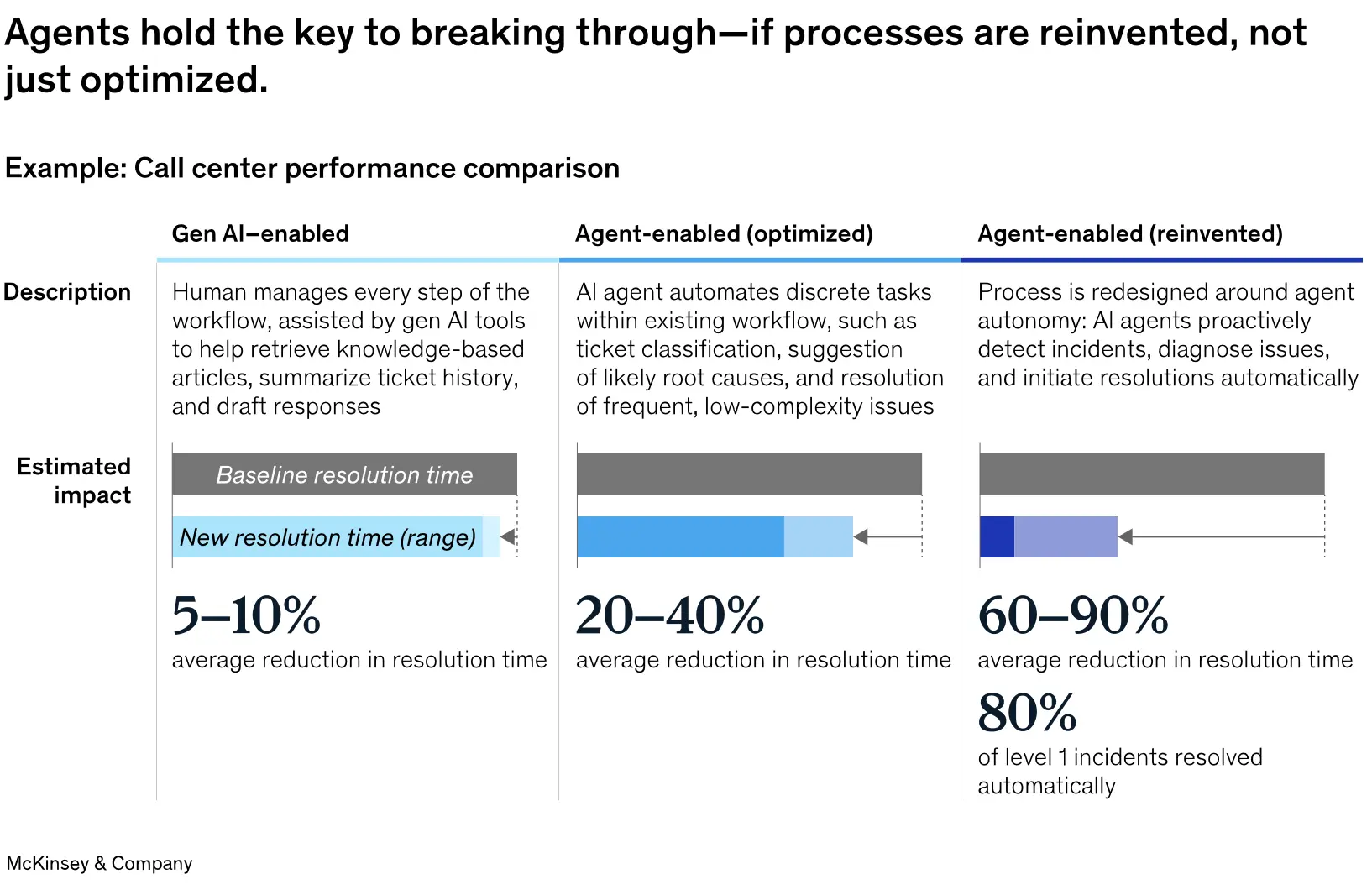
The report suggests that the real upside of agent adoption lies in process reinvention rather than incremental improvements. Three levels of impact are described: assistant overlays that provide modest productivity gains; step-level agent assistance that can significantly boost productivity and reduce backlogs; and agent-centric reimagination, which promises high rates of auto-resolution and dramatic reductions in time to resolution.
While the lack of material outcomes from most AI pilots is acknowledged, the proposed solution is to double down on AI—specifically, to move from generic LLM-based tools to more sophisticated, agent-driven architectures. The implication is that the next phase of enterprise AI will require not just more AI, but a fundamental shift in how organizations design, deploy, and govern these systems.
Source: https://www.mckinsey.com/capabilities/quantumblack/our-insights/seizing-the-agentic-ai-advantage
METR: rework for the PRs needed
METR’s follow-up research on the slowdown effect highlights a persistent gap between automated test results and real-world mergeability of agent-generated pull requests. Early-2025 coding agents frequently pass unit tests but still submit PRs that cannot be merged, suggesting that algorithmic scoring may not fully capture practical usefulness. SWE‑Bench Verified scores in the 70–75% range do not always translate to actual mergeable contributions.
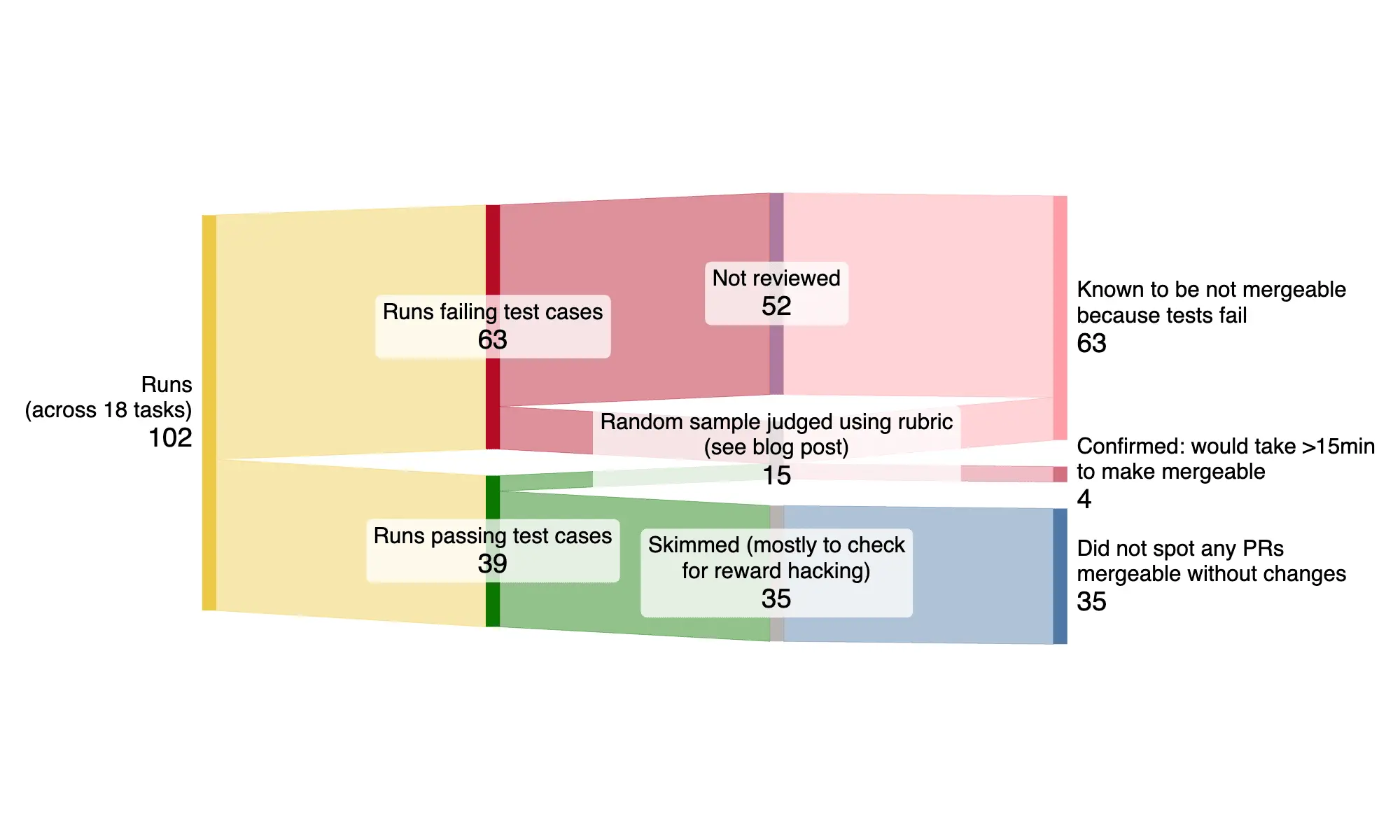
The quantitative results are stark: only 38% of PRs succeeded on maintainer tests, and none out of fifteen were mergeable on manual review. Human “time to fix” averaged 42 minutes, for tasks that on average took about 1.3 hours. The agent scaffold for this evaluation used Inspect ReAct with Claude 3.7 Sonnet, with tests hidden from the agent. Notably, the language models in this study did not have access to tools like deterministic linters.
The findings show that passing tests generally reflect correct core logic but miss non-verifiable work such as documentation, tests, linting, and readability. This helps explain the observed slowdown compared to earlier, more optimistic time-horizon estimates.
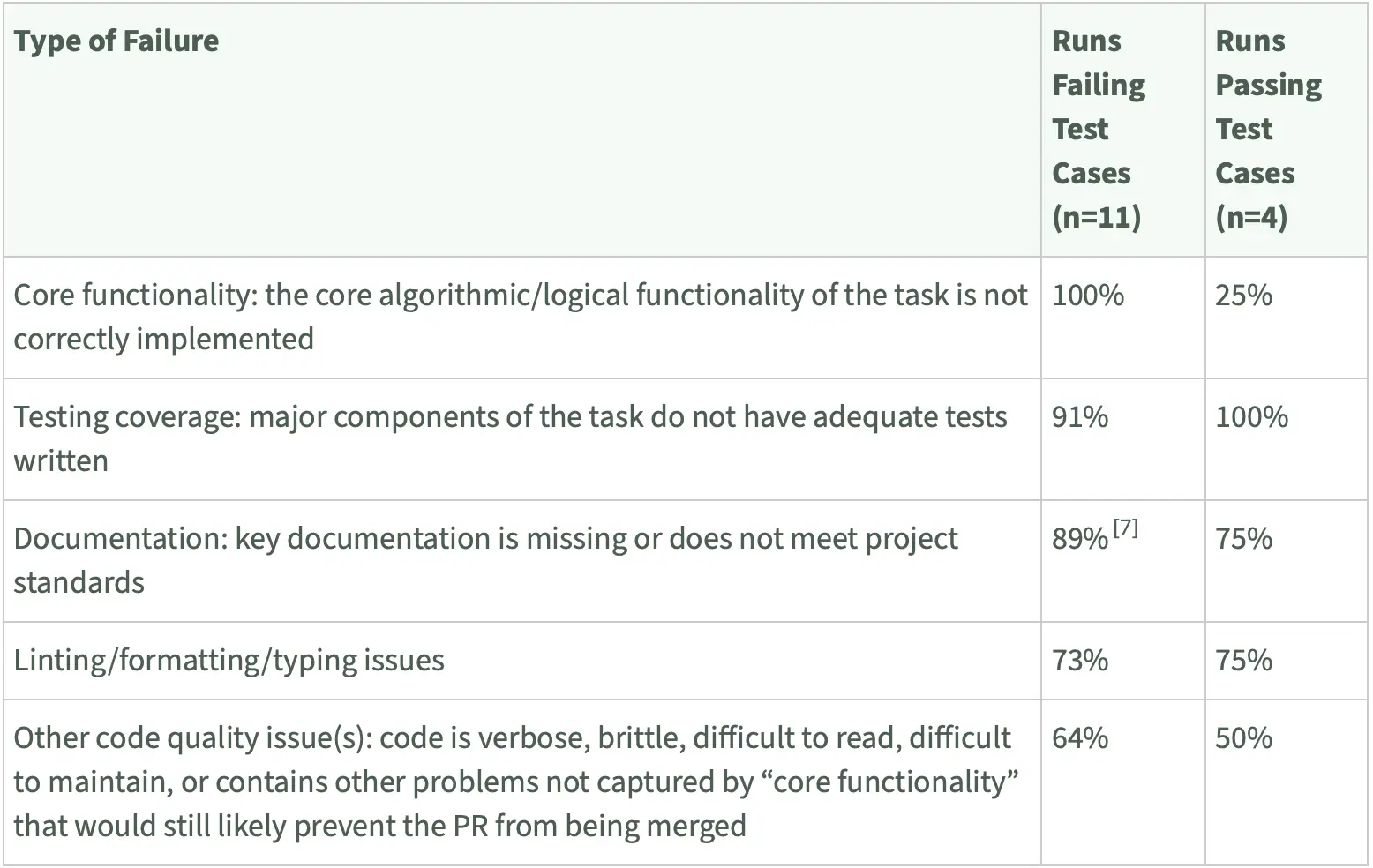
The research suggests that progress on softer objectives—like documentation and code quality—lags behind improvements in core logic. Tracking “time to fix” alongside pass rates provides a more complete picture of agent performance. The results indicate that incorporating holistic gates, such as documentation and readability, into agent evaluation is necessary to align automated metrics with real-world utility.
Source: https://metr.org/blog/2025-08-12-research-update-towards-reconciling-slowdown-with-time-horizons/
GitHub Copilot updates
- You can now create tasks for the GitHub Copilot coding agent from any page on github.com. For details, see Agents panel: Launch Copilot coding agent tasks anywhere on github.com.
- Gemini 2.5 Pro is generally available in Copilot. For details, see Gemini 2.5 Pro is generally available in Copilot.
- GitHub Copilot Knowledge Bases will be deprecated starting September 12th. They are being replaced by Copilot Spaces, which now handles project context management. For details, see Sunset notice: Copilot knowledge bases.
- Copilot can now generate commit messages when you make changes in the GitHub web interface. For details, see Copilot generated commit messages on github.com is in public preview.
- The Grok Code Fast model is now in public preview for Copilot. Performance details have not yet been released. For details, see Grok Code Fast 1 is rolling out in public preview for GitHub Copilot.
Cursor news
- Cursor now integrates with Linear. You can launch the Cursor coding agent directly from a Linear issue, with full access to the issue’s description, title, and comments. This allows you to delegate tasks to the agent from within your project management tool. Similar integrations with other tools, such as Jira, are likely to follow. For details, see Bringing the Cursor Agent to Linear.
- The agent can now send a system notification when it finishes its work or needs user input. For details, see the Cursor changelog.
- MCP Servers can now ask users for structured information using a new feature called MCP Elicitation. This feature lets you define required parameters with JSON schema. For details, see the Cursor changelog.
- The Grok 4 Code model is now available in Cursor. It was previously offered as a preview under the name sonic. For details, see Grok Code Out Now.

_(1).png?auto=webp)
.png?auto=webp)