
Advancing deterministic AI: innovations in tooling, governance, and ambient assistance
EPAM AI SDLC experts explore advancements in deterministic AI, standardized tooling practices, improved governance, and proactive background assistance to enhance reliability, scalability, and development efficiency.
This digest was prepared by:
- Alex Zalesov, Systems Architect
- Aliaksandr Paklonski, Director of Technology Solutions
- Tasiana Hmyrak, Director of Technology Solutions

This issue explores determinism, along with key advancements in AI tooling, governance, and ambient assistance:
- New research proposes batch‑invariant inference that could eliminate a core source of LLM non‑determinism. If this holds up in practice, enterprise AI shifts toward reproducible behavior closer to traditional software—easier debugging, reliable tests, and tighter change control.
- Tooling practice is also standardizing. Anthropic’s guidance on writing tools for agents codifies emerging best practices: narrow, opinionated tools that complete a unit of work, compact outputs, stable schemas, and actionable errors to support agent planning and retries.
- Finally, governance tightens with MCP registries. A public catalog and allowlists in Copilot make servers discoverable and policies enforceable, improving security, auditability, and integration into enterprise apps without vendor lock‑in.
- Ambient background assistance improves. GitHub Copilot’s Next Edit Suggestions (NES) and Cursor’s Tab completion proactively surface small, context‑aware edits based on editor state—cursor location, recent changes, and surrounding code—without an explicit prompt. The goal is low‑noise suggestions that “surface” for inline accept/decline, moving AI toward environment‑aware support that runs in the background.
General news
Writing effective tools for agents
Anthropic published a guide on how to build effective tools for AI agents.
Building tools for agents is not the same as exposing raw APIs. Traditional APIs assume deterministic callers that can compose many endpoints and handle edge cases. Agents are probabilistic, operate under tight context limits, and benefit from opinionated, workflow‑oriented tools that return compact, meaningful outputs.
Start from the highest‑impact workflows and design narrow tools that perform a complete unit of work. Prefer filtered and paginated responses over broad dumps, and return human‑interpretable identifiers and fields the agent can reason about. Support progressive disclosure with parameters (e.g., summary vs. details) so the agent can control verbosity without wasting tokens.
Make errors actionable. Instead of opaque codes or long tracebacks, emit concise messages that explain what went wrong and how to fix it (including valid ranges, required auth, or alternative parameters). Keep schemas stable and deterministic; document preconditions, side‑effects, and idempotency so agents can safely retry.
Invest in tool specifications. Clear names, precise descriptions, constraints, and a couple of short examples materially steer agent behavior. Avoid redundant or overlapping tools that fragment the surface area; fewer, well‑scoped tools generally lead to better performance and lower context usage.
Source: https://www.anthropic.com/engineering/writing-tools-for-agents
Deterministic LLMs
One persistent problem with LLMs is their non-determinism: running the same query multiple times can yield different results. This happens even if you set temperature to 0, which should always pick the most likely token. This differs LLMs from traditional computer programs, makes results hard to reproduce and slows adoption.
Thinking Machines, a startup founded by former OpenAI CTO Mira Murati, published a paper identifying the source of this non-determinism and showing how to make LLMs deterministic.
The root cause is floating-point arithmetic, which is non-associative due to limited precision. The order of operations matters: a + (b + c) is not always equal to (a + b) + c. During inference, multiple requests are processed in parallel as a batch. The researchers found that batch size may change the order of operations for each request, so the output for a single query can depend on what else is in the batch.
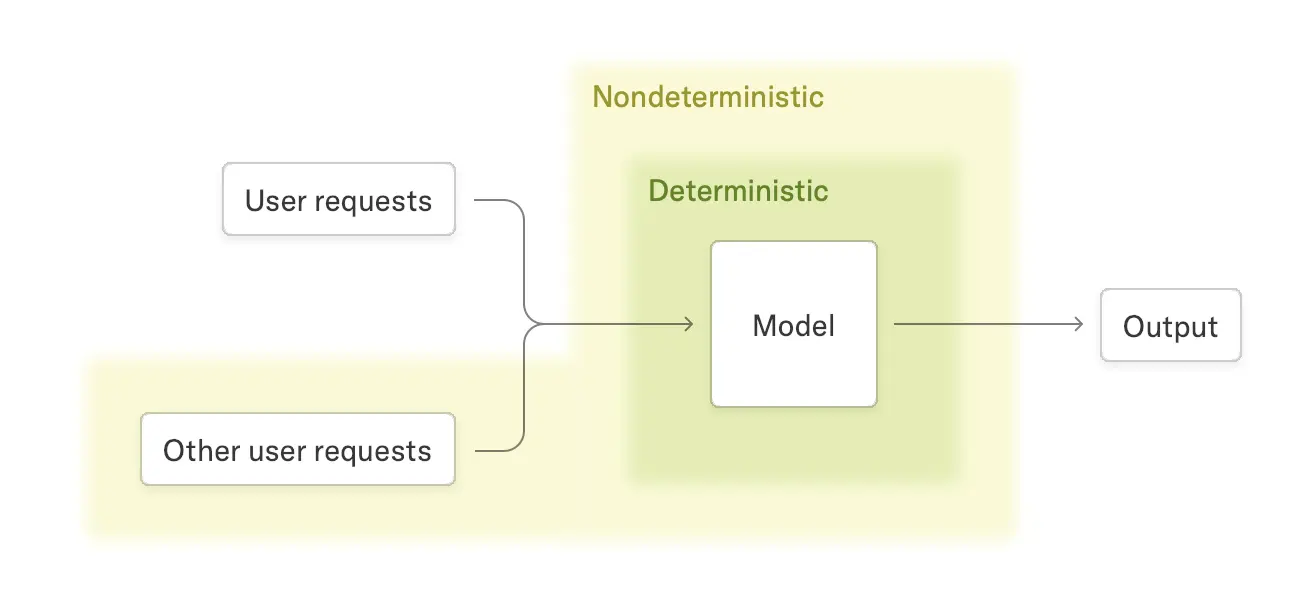
They propose a batch-invariant implementation that produces the same results regardless of what other requests are running in parallel. This is still research and not yet optimized for performance, but if it works out, we may soon see reproducible results from major LLM providers.
To clarify: you will get exactly the same output only when temperature is set to zero. With temperature not equal to zero, results will still vary because sampling is probabilistic. However, you can already control sampling with the seed parameter, and with batch-invariant inference, you will get the same output for a given query and seed pair.
Source: https://thinkingmachines.ai/blog/defeating-nondeterminism-in-llm-inference
MCP Registry preview: public catalog for discoverable MCP servers
The MCP Registry is an open, standardized catalog and API for Model Context Protocol (MCP) servers, created by the protocol’s authors with industry collaboration. The official open-source registry, live at https://registry.modelcontextprotocol.io, serves as the primary source of truth for MCP server metadata and supports both public and private sub-registries for use by marketplaces and client applications.
Currently, there are several catalogs of MCP servers, which causes duplicated information and fragments the ecosystem. The MCP Registry aims to be a single source of truth that other catalogs can build on and extend. It will be community-moderated, so malicious or low-quality entries will be removed from the main catalog.
This is a preview release: it is not production‑ready, offers no durability or warranty, and may introduce breaking changes before general availability. Treat it as foundational open‑source infrastructure for reliable, context‑aware AI applications and plan for evolution.
Registry maintainers: Adam Jones (Anthropic), Tadas Antanavicius (PulseMCP), and Toby Padilla (GitHub).
Source: https://blog.modelcontextprotocol.io/posts/2025-09-08-mcp-registry-preview/
GitHub news
Next Edit Suggestions (NES) for JetBrains (public preview)
GitHub Copilot's "Next Edit Suggestions" (NES) is now available in public preview for JetBrains IDEs. NES proactively suggests edits and improvements to your existing code as you work, helping maintain cleaner and more consistent codebases. To use it, enable NES in your JetBrains IDE settings, and suggestions will appear automatically as you code.
OpenAI’s GPT-5 and GPT-5 mini are now generally available in GitHub Copilot
Bring Your Own Key (BYOK) in JetBrains and Xcode
GitHub Copilot Chat now supports Bring Your Own Key (BYOK) in JetBrains IDEs and Xcode, allowing users to connect their own API keys from providers like Anthropic, Azure, Google Gemini, Groq, OpenAI, and OpenRouter. This enables greater model flexibility, experimentation, and control over which AI models are used, with easy setup through the Copilot plugins for supported IDEs.
Internal MCP registry and allowlist controls
Enterprise and organization administrators can now create an internal MCP registry and test strict “Registry only” allowlist enforcement in VS Code Insiders, ahead of a broader rollout across Copilot environments. The registry functions as a catalog of approved MCP servers that appear in the MCP servers sidebar for easy installation; when “Registry only” is enabled, any server not listed is blocked at runtime. This matters because many teams today fetch MCP servers directly from the internet with limited verification, creating avoidable security and compliance risk. Internal registries and policy‑backed allowlists turn that ad‑hoc model into governed discovery and enforceable usage.
Administrators can host a registry via Azure API Center for managed, dynamic governance, or serve a specification‑compliant JSON from any HTTPS endpoint (for example, GitHub Pages or S3) following the official MCP registry specification. In VS Code Insiders, both registry display and enforcement are available now. VS Code Stable currently displays registry servers but does not enforce the policy yet. Policy choices include “Allow all” (default), which treats the registry as recommendations, and “Registry only,” which restricts usage to listed servers. At present, local server enforcement validates against server IDs only; in October, enforcement will add stricter local configuration matching for command paths, arguments, and environment variables.
The rollout plan is phased: Insiders supports full enforcement today while Stable is display‑only; in October, enforcement and enhanced local matching arrive for VS Code Stable and Visual Studio; through October–November, integration extends to Copilot Coding Agent, JetBrains, Eclipse, and Xcode. The feature is available to Copilot Business and Copilot Enterprise customers, and where users have multiple seats, enterprise policies override organization policies.
Cursor updates
Cursor Tab: fewer, higher‑quality suggestions via online RL
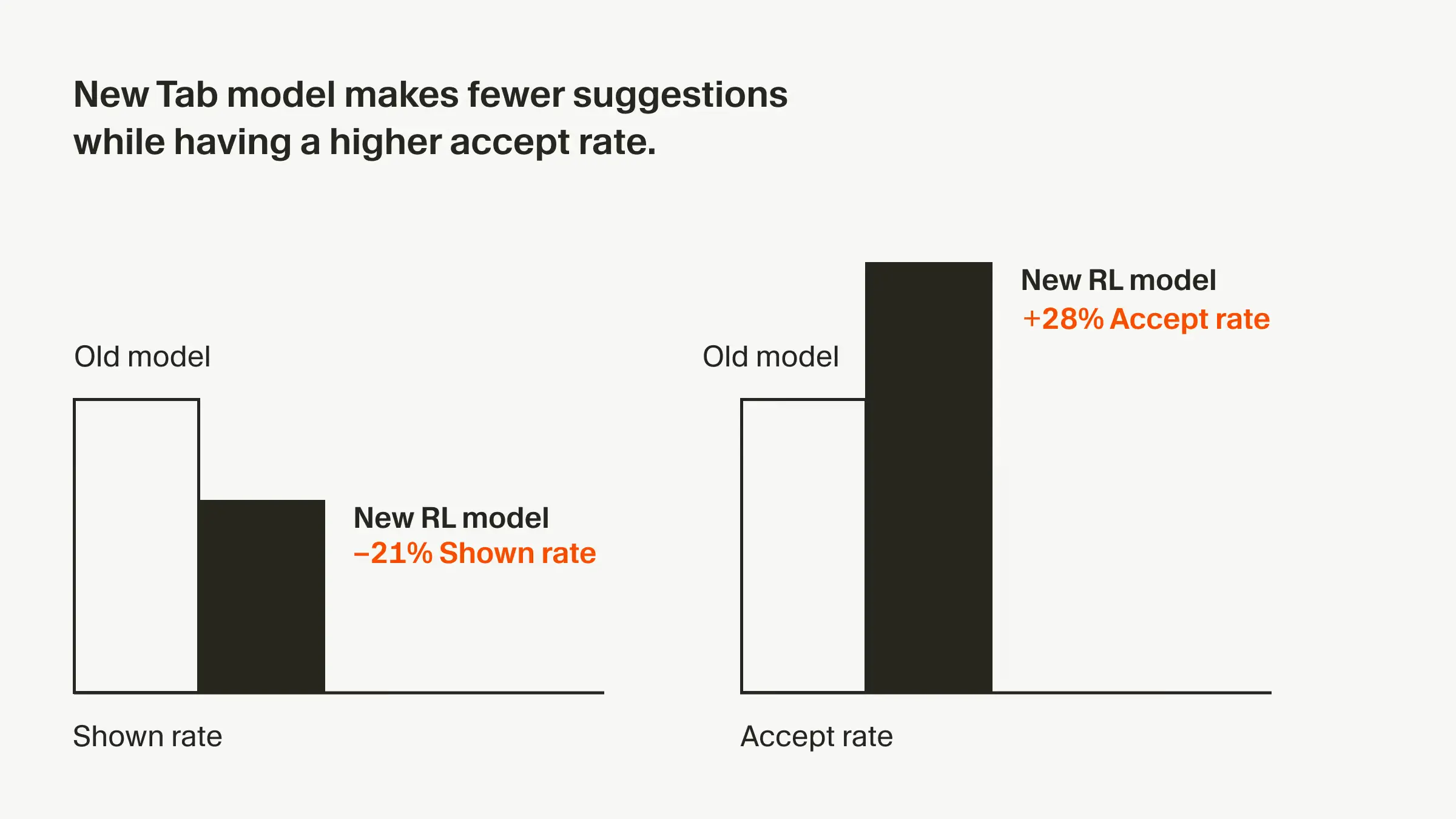
Cursor Tab predicts user actions in the editor and surfaces suggestions that can be accepted with the Tab key, with the goal of boosting developer productivity.
Unlike typical LLM providers that train on static datasets and ship infrequent updates, Cursor uses an online reinforcement learning approach. New models are rolled out frequently and retrained on real user data, supported by infrastructure that enables rollouts and data collection every 1.5–2 hours.
A key challenge is avoiding noisy suggestions that disrupt flow. High accept rates require not only smarter predictions but also knowing when not to suggest.
The latest Tab model makes 21% fewer suggestions while achieving a 28% higher accept rate versus its predecessor, resulting in fewer but better‑targeted prompts.
Source: https://cursor.com/blog/tab-rl

_(1).png?auto=webp)
.png?auto=webp)